


Recently I worked with Colin Jones from Blackjack Apprenticeship to build a new blackjack simulation framework. The simulation results help card counters to calculate optimal betting schemes for different table rules at different casinos. The tool is available to ~3000 card counters world wide as of July 2019. After simulating 5,761 different rule sets and 13,712,565,495,400 (13.7 trillion) hands I learned a lot about Blackjack, and how to optimize and scale workloads in the cloud.
The Problem
Casinos offer table games with different rules. This can be as simple as the number of decks used, e.g. 1, 2, 3, 4, 6, or 8, or as complex how and when a player is allowed to split aces. How the user plays also changes the simulation results. There is a large difference between playing basic strategy or using card counting to deviate from basic strategy. Deviations help to increase positive EV (expected value), and minimize negative EV, e.g. surrender a hard 15 against a dealer 9 at true count of +2.
I needed to build a framework that could simulate ~6k different table rules based on configurations. For each rule set, I needed to simulate ~2 billion hands to generate sufficient sample sizes.
The (first) Approach => Fail Fast
I got a working simulation for a single rule set in NodeJS in ~6 hours. And it was... slow... really slow. After a couple hours of trying to optimize the code, a 3x improvement wasn't enough. So naturally, I picked Java because... #yolo.
It actually turned out to be a lot faster than Node for CPU bound tasks.
!!! Important: CPU BOUND TASK, Java is not always faster/better than Node!!!
Since I am an Enterprise Java Architect, I had a pretty good idea about how to optimize and parallelize the work. The following logs were the result of running on a 2-ish core Java 8 AWS Lambda deployment.
simStats.getDuration() = 420,016 ms
simStats.getTotalHands() = 1,048,476,663
simStats.getHandsPerSecond() = 2,496,277.91
Architecture
The application was deployed to AWS Lambda because I wanted to take advantage of the on-demand scaling and billing.
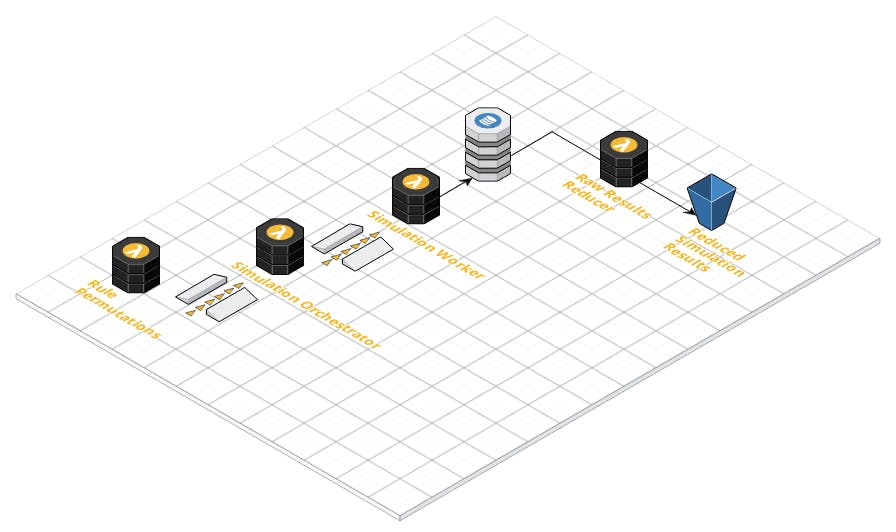
The Rules Permutations service would publish a single SQS message for each rule set. The Simulation Orchestrator service would break a rule set simulation into units of work. Each unit of work was sent over SQS to the Simulation Worker. The workers would write raw results to DynamoDB. After all simulations were complete, I would manually run the Raw Results Reducer service which reads and compiles all of the raw results into 5760 final result sets, each having ~2B simulated hands.
Performance + Surprises
I broke up the work so that each unit of work can be completed in ~7 minutes.
"Time for the power of the cloud to shine! I can publish ~12k messages on SQS and I should see ~10k parallel instances of my Lambda running. Everything should be done in ~30 minutes allowing for some time to scale up." - Me
All the serverless folks are probably laughing right now.
AWS Lambda only allows 1,000 instances across ALL of your lambda functions. To be explicitly clear, you share that max quota of 1,000 across all functions. This means that I could only run 1,000 simulations in parallel... bummer.
At this point, I took a deep breath, considered my foolish assumptions and converted my code to run on multiple CPU's. To make sure I didn't shoot any more feet, I ran performance tests on every memory (and implicitly CPU) deployment setting AWS offers. The optimum ratio was running on the max memory setting, 3008 MB. I am not actually sure that they have a full 3 core deployment setting but this is pretty close. And since my Lambda is CPU bound, any memory thrashing / thread swapping is REALLY expensive.
Results by the Numbers
| Total Rules | 5,760 |
| Total Hands | 13.7 trillion |
| Hands / CPU / sec | ~1.2 million |
| Hands / Lambda / sec | ~2.4 million |
| Hands / sec | ~2.4 billion (MAX) |
| Hands / hour | ~8.7 trillion (MAX) |
| Hands / sec | 952 million (AVG) |
| Hands / hour | ~3.4 trillion (AVG) |
Why is the average hands/sec less than the max? Remember that I sent ~5k messages to the Orchestrator which then broke up the work and sent it down the Workers. Because I was trying to scale to handle ~17k lag between the two topics there was some thrashing and scheduling issues slowing down the worker simulations. Way too many pigeons if you ask me.
Next Time
I would NOT deploy it on AWS Lambda. However, I am interested in trying out Google Cloud Run leveraging PubSub triggers. This allows for the same flexible scaling and billing. But there are a few other things that I can potentially leverage to push the limits even further:
- Maximum number of instances is 1,000 per service. I could just deploy the same container under multiple services and have all of them subscribe to the same PubSub topic.
Worker#1, Worker#2, ...:) - Maximum timeout is 15 minutes instead of AWS Lambda's 9 minutes.
- The max container size is only 2GB of memory which is probably ~0.5 CPU. But Cloud Run also supports deploying to GKE where I can specify any node size.
Until Next Time
If you are interested in hearing more about blackjack formulas and calculations, reach out; or if you are interested some of the memory and CPU optimization I made let me know and I can make a followup post.